
2 条题解
-
6
作者吐槽
这些题怎么都有 洛谷 原题啊。
原题:洛谷P4092
题解
思路1
同样使用“离线+并查集”,准确的说可以叫“拆查集”。
为什么使用
拆查集我们看这道题,让我们寻找最近的一个已标记祖先。
忘掉并查集,我们很容易就想到可以向上一直找该点的父亲,直到找到标记的点。这种暴力的方法,缺点在于哪里?在于每次查询都要向上 去找祖先。
有没有什么办法可以缩短这个过程?
倍增?不太行,我们要找到一个确定的点。
事实上,我们可以使用“路径压缩”,将点跳过父亲,直接找到已标记祖先。
看起来很好,但事实上,有一个问题:
并查集,并查集,是合并森林中的子树,而按照这道题,我们应当在“标记”时让一个点自环变成其子孙的“已标记祖先”,这显然是把树拆成了森林,在并查集中并不容易实现,尤其是我们还使用了路径压缩。
这类需要“拆”并查集的问题有一个类似的解决办法,就是“离线”再倒序处理。我们可以假装我们完成了所有操作,把点们变成一个森林(最终结果)。再倒着处理操作,将“拆”化为“并”,就可以得到这次操作之前的样子,从而再
find(x)求出该点在未操作状态下的“已标记祖先”。有点复杂,贴个图:
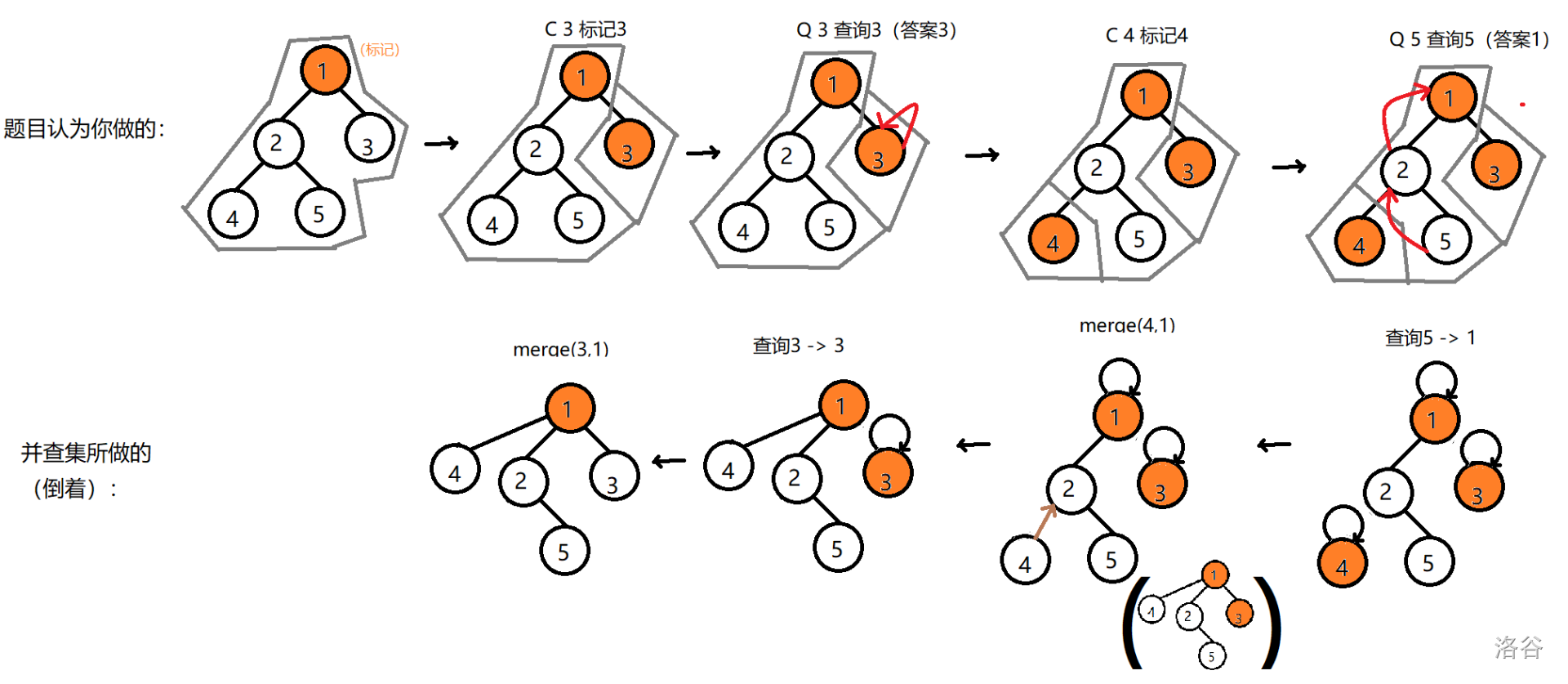
现在你大概能了解“拆查集”是一种怎样的东西了。我们正是利用了“拆查集”来解决这道题,当然,倒序的必须原因“离线”必须实现。
所以这里就展示一下输入的代码:
struct ques // 离线,存储问题的结构体 { bool ty; // ty 操作类型 int id, ans; // id 操作对象 ans 答案 } p[100005]; void add(int x, int y) { adj[x].push_back(y); // vector存图 //也可以链式前向星 } scanf("%d%d", &n, &q); for (int i = 1; i <= n - 1; i++) { scanf("%d%d", &in1, &in2); // 加边,注意是无向边 add(in1, in2); add(in2, in1); } for (int i = 1; i <= q; i++) { scanf("%s%d", inp, &p[i].id); // inp表示oper,p[i].id就是操作对象 switch (inp[0]) // 这里使用了switch - case { case 'Q': { p[i].ty = 0; // 保存类型 break; } case 'C': { p[i].ty = 1; // 保存类型 ++col[p[i].id]; // 同时标记上色,这样循环完毕,col就是最终结果的染色情况,拿去构建并查集 break; } } }注意这里我使用了一个
switch - case,其实它等价于这个:if (inp[0] == 'Q') { ... } else if (inp[0] == 'C') { ... }
粗略介绍一下,语法如下:
switch (X) { case A: ... case B: ... case C: ... ... default: ... }作用是压缩很多的
if - else if,分别在X==A、X==B...这些时候执行对应的代码。我所写的输入代码中还用了大括号,其实不必要,但是更加直观可读。default则是上述条件均不满足所执行的条件。
某些
switch - case还会有break;出现,这是break的另一用法,在默认情况下,程序会从X==A一直尝试到最后一个,不管其中是否有成功的。但是default只有都不满足才会触发。就像这样:d = 5; switch (d) { case 4: printf("A"); case 5: printf("B"); case 6: printf("C"); default: printf("\nDEFAULT!!!"); }输出是
B,但是case 6也测试过了,但不符合,所以没有输出C。加了
break;之后,一个成功,整个跳过。switch - case只能判断相等,而不能判断复杂表达式,以及不能重复判定某一点:d = 5; switch (d) { case 4: printf("A"); case 5: printf("B"); case 6: printf("C"); case 4 + 1: printf("D"); // 这会报错 case 6 - 1: printf("E"); // 这会报错 default: printf("\nDEFAULT!!!"); }使得其没有
if - else if灵活,从而不能广泛使用。但是这仍然是一个重要的语法。
接下来我们需要进行 ,这一操作的目的是,使用 染色数组构造结果并查集。
int col[100005]; // 记录是否染色 int ufs[100005]; // 并查集数组 int f[100005]; // 记录点的父亲 void dfs(int u, int fa) // u表示本点,fa表示父亲 { if (col[u]) ufs[u] = u; // 如果自己染色,就让值等于自己 else ufs[u] = fa; // 否则等于父亲 f[u] = fa; // 顺便记录父亲 for (int i = 0; i < adj[u].size(); i++) // vector存图 { int v = adj[u][i]; if (v == fa) continue; // 不去来路 dfs(v, u); } } inline int find(int x) // 并查集标准操作,inline给加个速,但是不可以给太复杂的函数加inline { return x == ufs[x] ? x : ufs[x] = find(ufs[x]); // 路径压缩 }这个应该没什么问题。接下来是最重要的部分,也就是还原并查集和求取答案。
// 接下来就是最重要的部分 for (int i = q; i >= 1; i--) { if (p[i].ty) // 操作C { col[p[i].id]--; // 取消染色 if (!col[p[i].id]) // “并”查集 ufs[p[i].id] = f[p[i].id]; // 这个点没有染色了 } else // 操作Q { // 并“查”集 p[i].ans = find(p[i].id); // 计入答案 } }很重要但是很好理解。最后一个顺次输出:
// 最后顺次输出答案 for (int i = 1; i <= q; i++) { if (!p[i].ty) { printf("%d\n", p[i].ans); } }在给出代码之前我使用两种存图方式,“邻接表”和“链式前向星”,各写了一份代码,这里不赘述两者的原理,但是可以以这个代码为例子了解“链式前向星”,不要被名字吓到。
邻接表完整代码:
#include <bits/stdc++.h> using namespace std; int n, q, in1, in2; char inp[3]; // 其实就是缓存输入的oper,因为string在switch中有诸多问题,所以使用char[]更加保险 vector<int> adj[100005]; int col[100005]; // 记录是否染色 int ufs[100005]; // 并查集数组 int f[100005]; // 记录点的父亲 struct ques // 离线,存储问题的结构体 { bool ty; // ty 操作类型 int id, ans; // id 操作对象 ans 答案 } p[100005]; void add(int x, int y) { adj[x].push_back(y); } void dfs(int u, int fa) // u表示本点,fa表示父亲 { if (col[u]) ufs[u] = u; // 如果自己染色,就让值等于自己 else ufs[u] = fa; // 否则等于父亲 f[u] = fa; // 顺便记录父亲 for (int i = 0; i < adj[u].size(); i++) // vector存图 { int v = adj[u][i]; if (v == fa) continue; // 不去来路 dfs(v, u); } } inline int find(int x) // 并查集标准操作,inline给加个速,但是不可以给太复杂的函数加inline { return x == ufs[x] ? x : ufs[x] = find(ufs[x]); // 路径压缩 } int main() { scanf("%d%d", &n, &q); for (int i = 1; i <= n - 1; i++) { scanf("%d%d", &in1, &in2); // 加边,注意是无向边 add(in1, in2); add(in2, in1); } col[1] = 1; // 给1号点染色 for (int i = 1; i <= q; i++) { scanf("%s%d", inp, &p[i].id); // inp表示oper,p[i].id就是操作对象 switch (inp[0]) // 这里使用了switch - case { case 'Q': { p[i].ty = 0; // 保存类型 break; } case 'C': { p[i].ty = 1; // 保存类型 ++col[p[i].id]; // 同时标记上色,这样循环完毕,col就是最终结果的染色情况,拿去构建并查集 break; } } } dfs(1, 0); f[1] = 1; // 注意1点的自环 // 接下来就是最重要的部分 for (int i = q; i >= 1; i--) { if (p[i].ty) // 操作C { col[p[i].id]--; // 取消染色 if (!col[p[i].id]) // “并”查集 ufs[p[i].id] = f[p[i].id]; // 这个点没有染色了 } else // 操作Q { // 并“查”集 p[i].ans = find(p[i].id); // 计入答案 } } // 最后顺次输出答案 for (int i = 1; i <= q; i++) { if (!p[i].ty) { printf("%d\n", p[i].ans); } } return 0; }链式前向星完整代码:
#include <bits/stdc++.h> using namespace std; int n, q, in1, in2; char inp[3]; // 其实就是缓存输入的oper,因为string在switch中有诸多问题,所以使用char[]更加保险 int edv[100005 << 1], ednxt[100005 << 1]; // 链式前向星 int first[100005], cnt = 0; int col[100005]; // 记录是否染色 int ufs[100005]; // 并查集数组 int f[100005]; // 记录点的父亲 struct ques // 离线,存储问题的结构体 { bool ty; // ty 操作类型 int id, ans; // id 操作对象 ans 答案 } p[100005]; void add(int x, int y) { edv[++cnt] = y; ednxt[cnt] = first[x]; first[x] = cnt; } void dfs(int u, int fa) // u表示本点,fa表示父亲 { if (col[u]) ufs[u] = u; // 如果自己染色,就让值等于自己 else ufs[u] = fa; // 否则等于父亲 f[u] = fa; // 顺便记录父亲 for (int i = first[u]; i; i = ednxt[i]) // 链式前向星 { int v = edv[i]; if (v == fa) continue; // 不去来路 dfs(v, u); } } inline int find(int x) // 并查集标准操作,inline给加个速,但是不可以给太复杂的函数加inline { return x == ufs[x] ? x : ufs[x] = find(ufs[x]); // 路径压缩 } int main() { scanf("%d%d", &n, &q); for (int i = 1; i <= n - 1; i++) { scanf("%d%d", &in1, &in2); // 加边,注意是无向边 add(in1, in2); add(in2, in1); } col[1] = 1; // 给1号点染色 for (int i = 1; i <= q; i++) { scanf("%s%d", inp, &p[i].id); // inp表示oper,p[i].id就是操作对象 switch (inp[0]) // 这里使用了switch - case { case 'Q': { p[i].ty = 0; // 保存类型 break; } case 'C': { p[i].ty = 1; // 保存类型 ++col[p[i].id]; // 同时标记上色,这样循环完毕,col就是最终结果的染色情况,拿去构建并查集 break; } } } dfs(1, 0); f[1] = 1; // 注意1点的自环 // 接下来就是最重要的部分 for (int i = q; i >= 1; i--) { if (p[i].ty) // 操作C { col[p[i].id]--; // 取消染色 if (!col[p[i].id]) // “并”查集 ufs[p[i].id] = f[p[i].id]; // 这个点没有染色了 } else // 操作Q { // 并“查”集 p[i].ans = find(p[i].id); // 计入答案 } } // 最后顺次输出答案 for (int i = 1; i <= q; i++) { if (!p[i].ty) { printf("%d\n", p[i].ans); } } return 0; }思路2
这个思路就比较生僻,叫做树剖。上面思路能成功就在于没有“强制在线”,
否则就GG了。其实上面思路的图已经有一点树剖的味道了。这题是个裸的树剖,准确说,正解应该是树剖。
树剖 是把一棵树剖解成几条链,以便像处理序列一样处理一些树上区间——路径问题的一种算法。两者的矛盾在于“树上一个节点可以有多个后继,而链上的一个节点最多只能有一个后继,也就是()”,而能有许多种不同的树剖,就在于选择后继的条件。
这里先不展开说了。
#include <bits/stdc++.h> using namespace std; int n, q, in1, in2; char inp[3]; vector<int> adj[100005]; int col[100005]; int ufs[100005]; int f[100005]; struct ques { bool ty; int id, ans; } p[100005]; void add(int x, int y) { adj[x].push_back(y); } void dfs(int u, int fa) { if (col[u]) ufs[u] = u; else ufs[u] = fa; f[u] = fa; for (int i = 0; i < adj[u].size(); i++) { int v = adj[u][i]; if (v == fa) continue; dfs(v, u); } } inline int find(int x) { return x == ufs[x] ? x : ufs[x] = find(ufs[x]); } int main() { scanf("%d%d", &n, &q); for (int i = 1; i <= n - 1; i++) { scanf("%d%d", &in1, &in2); add(in1, in2); add(in2, in1); } col[1] = 1; for (int i = 1; i <= q; i++) { scanf("%s%d", inp, &p[i].id); switch (inp[0]) { case 'Q': { p[i].ty = 0; break; } case 'C': { p[i].ty = 1; ++col[p[i].id]; break; } } } dfs(1, 0); f[1] = 1; for (int i = q; i >= 1; i--) { if (p[i].ty) { col[p[i].id]--; if (!col[p[i].id]) ufs[p[i].id] = f[p[i].id]; } else { p[i].ans = find(p[i].id); } } for (int i = 1; i <= q; i++) { if (!p[i].ty) { printf("%d\n", p[i].ans); } } return 0; }#include <bits/stdc++.h> using namespace std; int n, q, in1, in2; char inp[3]; int edv[100005 << 1], ednxt[100005 << 1]; int first[100005], cnt = 0; int col[100005]; int ufs[100005]; int f[100005]; struct ques { bool ty; int id, ans; } p[100005]; void add(int x, int y) { edv[++cnt] = y; ednxt[cnt] = first[x]; first[x] = cnt; } void dfs(int u, int fa) { if (col[u]) ufs[u] = u; else ufs[u] = fa; f[u] = fa; for (int i = first[u]; i; i = ednxt[i]) { int v = edv[i]; if (v == fa) continue; dfs(v, u); } } inline int find(int x) { return x == ufs[x] ? x : ufs[x] = find(ufs[x]); } int main() { scanf("%d%d", &n, &q); for (int i = 1; i <= n - 1; i++) { scanf("%d%d", &in1, &in2); add(in1, in2); add(in2, in1); } col[1] = 1; for (int i = 1; i <= q; i++) { scanf("%s%d", inp, &p[i].id); switch (inp[0]) { case 'Q': { p[i].ty = 0; break; } case 'C': { p[i].ty = 1; ++col[p[i].id]; break; } } } dfs(1, 0); f[1] = 1; for (int i = q; i >= 1; i--) { if (p[i].ty) { col[p[i].id]--; if (!col[p[i].id]) ufs[p[i].id] = f[p[i].id]; } else { p[i].ans = find(p[i].id); } } for (int i = 1; i <= q; i++) { if (!p[i].ty) { printf("%d\n", p[i].ans); } } return 0; } -
1

#include <bits/stdc++.h> using namespace std; const int N=100005; int n,m,k,s,t,ans[N],a[N],fa[N],pos[N],f[N]; char c[N]; vector<int> e[N]; void dfs(int u){ if (pos[u]) fa[u]=u; else fa[u]=f[u]; for (int &v:e[u]){ if (v==f[u]) continue; f[v]=u; dfs(v); } } int getfa(int u){ return u==fa[u]?u:fa[u]=getfa(fa[u]); } int main(){ cin>>n>>m; for (int i=1;i<n;++i){ cin>>s>>t; e[s].push_back(t); e[t].push_back(s); } pos[1]=-1; for (int i=1;i<=m;++i){ cin>>c[i];cin>>a[i]; if (c[i]=='C' && pos[a[i]]==0) pos[a[i]]=i; } f[1]=0; dfs(1); for (int i=m;i>=1;--i){ s=getfa(a[i]); if (c[i]=='Q') ans[i]=s; else if (pos[a[i]]==i) fa[s]=f[s]; } for (int i=1;i<=m;++i) if (c[i]=='Q') cout<<ans[i]<<"\n"; }
- 1