
6 条题解
-
3
大概整理了一下课上老师讲的思路。
写了个可能更易懂的代码。题目分析
- 此题的关键在于如果区间中有重复的数只能计算一次,可以考虑记数从左至右最后出现的数,也可以考虑记数最先出现的数,这里考虑最先出现的数。
- 如何确认是第一次出现的数?可以开一个数组 表示前一个与第 个数相同的数的下标。显然,对于区间 ,如果 且 ,那么 就是区间 中第一次出现。这时问题就可以转化为求 内有多少个 满足 。这个问题也可以差分,先求 的再求 的,又因为没有修改操作可以离线处理,于是乎就可以用树状数组求解。
- 代码实现时,将所有询问区间的左右端点放在一块从小到大排序,用类似于树状数组求逆序对的方法对每一个端点值求解,最后再合并询问区间,总时间复杂度 。
code:
#include <bits/stdc++.h> using namespace std; const int MAXN = 2e6 + 5; int pre[MAXN], c[MAXN], last[MAXN], n, m, a[MAXN]; struct node { int l , r, id, ans; } q[MAXN], p[MAXN]; bool cmp1(node x, node y) { return x.id < y.id; } bool cmp2(node x, node y) { return x.r < y.r; } int lowbit(int x) { return x & -x; } void update(int x, int y) { if (x == 0) c[0] += y;//这里要注意,pre[x]可能为0 else while(x < MAXN) { c[x] += y; x += lowbit(x); } } int query(int x) { int res = 0; while(x) { res += c[x]; x -= lowbit(x); } return res + c[0]; } int main() { ios::sync_with_stdio(false); cin.tie(0); cin >> n; for (int i = 1; i <= n; i++) cin >> a[i]; for (int i = 1; i <= n; i++) { pre[i] = last[a[i]];//求解pre[i] last[a[i]] = i; } cin >> m; int cnt = 0; for (int i = 1; i <= m; i++) { cin >> q[i].l >> q[i].r; q[i].id = i; p[++cnt] = (node){q[i].l-1, q[i].r, i, 0}; p[++cnt] = (node){q[i].l-1, q[i].l-1, i, 0};//拆分左右端点 } sort(p+1, p+cnt+1, cmp2); int R = 1; for (int i = 1; i <= cnt; i++) { //cout <<p[i].r << ' '; while(R <= p[i].r) { update(pre[R], 1); R++;//求解每一个端点 } p[i].ans = query(p[i].l); } sort(p+1, p+cnt+1, cmp1); for (int i = 1, j = 1; i <= m; i++, j += 2) { q[i].ans = max(p[j].ans, p[j+1].ans) - min(p[j].ans, p[j+1].ans); cout << q[i].ans << '\n'; } return 0; } -
2
 hetao2863173
LV 10
@ 2023-5-23 20:45:31
hetao2863173
LV 10
@ 2023-5-23 20:45:31
如果在线查询,更新的话,复杂度会很大,所以我们采用离线的处理方法。
主要是我们可以把查询按r排序,这样我们更新的时候就是nlogn的了。
那么具体的实现就还是前缀和,我们按查询来更新树状数组,假如到了现在这个点,它没在当前树状数组出现过,就加上1;如果出现过,那么就减去前面的1,再在现在这个点加上一,避免重复;
因为右边界是排过序的,所以不会影响答案的正确性:
/*keep on going and never give up*/ #include<bits/stdc++.h> using namespace std; #define int long long #define MAX 0x3f3f3f3f #define fast std::ios::sync_with_stdio(false);cin.tie(0);cout.tie(0); int const maxn=2e6+10; int n,m,p,x,y; int a[maxn],t[maxn],vis[maxn],ans[maxn]; struct node{ int l,r,id; }ask[maxn<<1]; bool cmp(node a,node b){ return a.r<b.r; } int lowbit(int x) {return x&-x;} void init(){ for(int i=1;i<=n;i++){ t[i]+=a[i]; int j=i+lowbit(i); if(j<=n) t[j]+=t[i]; } } void add(int u,int v){ for(int i=u;i<=n;i+=lowbit(i)) t[i]+=v; } int t_sum(int u){ int res=0; for(int i=u;i>0;i-=lowbit(i)) res+=t[i]; return res; } signed main(){ fast cin>>n; for(int i=1;i<=n;i++) cin>>a[i]; cin>>m;for(int i=1;i<=m;i++) cin>>ask[i].l>>ask[i].r,ask[i].id=i; sort(ask+1,ask+1+m,cmp); p=1; for(int i=1;i<=m;i++){ for(int j=p;j<=ask[i].r;j++){ if(vis[a[j]]) add(vis[a[j]],-1); add(j,1); vis[a[j]]=j; } p=ask[i].r+1; ans[ask[i].id]=t_sum(ask[i].r)-t_sum(ask[i].l-1); } for(int i=1;i<=m;i++) cout<<ans[i]<<endl; } /* int kth(int k){ int cnt=0,ret=0; for(int i=log2(n);~i;i--){ //i即depth ret+=1<<i;// 尝试扩展 if(ret>=n||cnt+t[ret]>=k)// 如果扩展失败 ret-=1<<i; else cnt+=t[ret];// 扩展成功后 要更新之前求和的值 } return cnt; } */ /* //多组数据时间戳优化 int tag[maxn],Tag; void reset(){++Tag;} void add(int k, int v) { while(k<=n) { if(tag[k]!=Tag)t[k]=0; t[k]+=v,tag[k]=Tag; k+=lowbit(k); } } int getsum(int k){ int ret=0; while(k) { if(tag[k]==Tag)ret+=t[k]; k-=lowbit(k); } return ret; } */我吐了啊,太难了
其实这题有好多做法,线段树,树状数组,莫队啊
暴力的话可以使用莫队来做
离线的话可以使用排序加树状数组或者线段树来做
强制在线可以使用主席树来做
介绍下吧
主席树
【算法分析】 主席树名称来源于其发明人黄嘉泰的姓名的首字母缩写HJT与我们某位主席姓名的首字母缩写一样。 主席树的经典应用在于求某个区间内的第K小/大数的值。比如区间第K大问题,就是给定一个数列a,询问给定区间[L,R]的第K大值。如对数列a=[4,1,3,2,5],针对询问L=2,R=5,K=2,其答案为2。
主席树是一种可持久化数据结构,即可持久化权值线段树。
为了实现可持久化,就要保存线段树的历史版本。最自然的想法是每进行一次修改,就新建一棵线段树,显然这样的空间复杂度是无法接受的。通过观察不难发现,每次单点修改,发生变化的只有从叶结点到根结点这一条路径上的结点。换句话说,只有log₂n个结点发生了变化,而其他的结点都可以重用,没有必要新建。
权值线段树一般开32倍空间,而普通线段树一般开4倍空间。若构建主席树,需先了解权值线段树的构建过程。 权值线段树以给定序列的值域作为区间进行结点构建。权值线段树每个结点存储的是所示值域上值的个数。
有n个结点的主席树,包含n棵权值线段树。n棵权值线段树的形状是一模一样的,只是结点的权值不一样。
下面给出构建权值线段树实例的具体步骤(【AgOHの数据结构】主席树_哔哩哔哩_bilibili):
1.给定序列1,1,2,3,3,3,4,4,显见其值域为[1,4]。 2.以区间[1,4]作为根结点所示区间构建线段树(与构建普通线段树方法一致)。 3.从叶子结点开始,由下向上,将第2步所建线段树中各个结点的权值赋值为其所示区间对应的原始序列中相应元素的个数,就构建成了一棵权值线段树。如区间[1,1]结点,其值为给定序列中1的个数2;区间[3,3]结点,其值为给定序列中3的个数3;区间[1,4]结点,其值为给定序列中1、2、3、4的总个数8。可见,权值线段树中的结点相当于桶排序中的桶。
由上算法,依据给定序列1,1,2,3,3,3,4,4创建的权值线段树示意图如下:
主席树是所有历史版本的权值线段树的集合。所以利用主席树,可以查询历史版本的权值线段树。 主席树构建时,若给定数据的个数大于100000,需采用离散化方法。所谓离散化,就是把无限空间中有限的个体映射到有限的空间中去,以提高算法的时空效率。通俗的说,离散化是在不改变数据相对大小的前提下,对数据进行相应的缩小。例如:25957,6405,15770,26287,26465离散化的结果为3,1,2,4,5
这是例子,不是答案
#include <bits/stdc++.h> using namespace std; const int maxn=1e5+10; struct node { int l,r,sum; } t[maxn<<5]; int cnt; int root[maxn]; int a[maxn]; vector<int>v; int getid(int x) { return lower_bound(v.begin(),v.end(),x)-v.begin()+1; } void insert(int l,int r,int pre,int &now,int p) { t[++cnt]=t[pre]; now=cnt; t[now].sum++; if (l==r) { return; } int mid=(l+r)>>1; if (p<=mid) { insert(l,mid,t[pre].l,t[now].l,p); } else { insert(mid+1,r,t[pre].r,t[now].r,p); } } int query(int l,int r,int L,int R,int k) { if (l==r) return l; int mid=(l+r)>>1; int tmp=t[t[R].l].sum-t[t[L].l].sum; if (k<=tmp) { return query(l,mid,t[L].l,t[R].l,k); } else { return query(mid+1,r,t[L].r,t[R].r,k-tmp); } } int main() { int n,m; cin>>n>>m; for (int i=1; i<=n; i++) { cin>>a[i]; v.push_back(a[i]); } sort(v.begin(),v.end()); v.erase(unique(v.begin(),v.end()),v.end()); for (int i=1; i<=n; i++) { insert(1,n,root[i-1],root[i],getid(a[i])); } while (m--) { int l,r,k; cin>>l>>r>>k; cout<<v[query(1,n,root[l-1],root[r],k)-1]<<endl; } return 0; } /* in: 8 2 12 7 9 31 6 90 77 11 2 7 5 3 8 3 out: 77 11 */莫队
莫队算法概述: 莫队算法是由莫涛发明的算法,所以称为莫队算法。 莫队算法是一个对于区间、树或其他结构离线(在线)维护的算法,此算法基于一些基本算法,例如暴力维护,树状数组,分块,最小曼哈顿距离生成树,对其进行糅合从而产生的算法 其主要用来处理离线的区间问题,如区间和。看到这你会想到线段树,但是他与线段树相比,优点就是可以处理离散的信息,而且代码量小。
算法过程: 对于多段区间的询问,先将询问区间离线存储下来,然后再从左到右扫一遍,在过程中维护一段区间,就可以得到每个寻问区间的答案. 但是暴力扫肯定不行,所以在扫之前,要对所有询问区间进行一番操作——sort!使得能够在移动次数最少的情况下,得到所有询问的区间. sort之前要先分块:为每一个询问区间添加一个变量——块号。将数轴上的n个数字分为 n \sqrt{n} 个数字,每一个询问区间的块号就是该区间的左端点所在的块号。 sort的规则:对于两个询问区间,若其块号相同(即 l 所在的块相同),那么将其 r 作为关键字从小到大排序;若其块号不同(即 l 所在的块不相同),就将 l 作为关键字从小到大排序。 这样排序后,维护全局的左右指针,使得它每次指向询问区间的左端点和右端点。从左到右扫一遍,处理每一个询问区间,计算答案了。 排序后的询问区间的移动如下图中蓝色区间向绿色区间的移动。
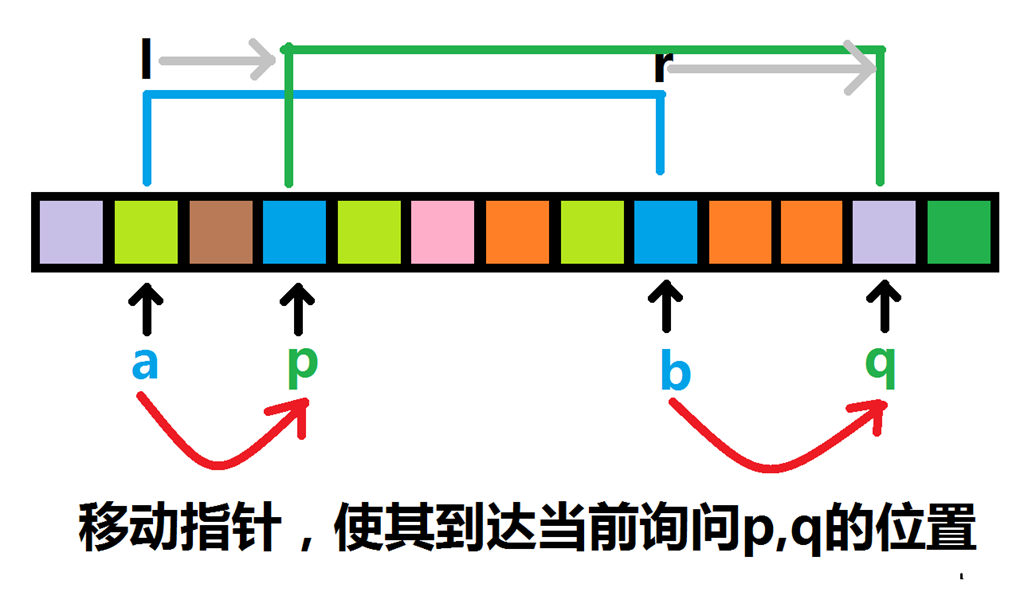
分类讨论:
① l l l 的移动:若下一个询问与当前询问的 l l l 所在的块不同,那么只需要经过最多 2 ∗ s i z e 2size 2∗size步可以使得 l l l成功到达目标。复杂度为: O ( m ∗ s i z e ) O(msize) O(m∗size)
② r r r 的移动: r r r 只有在区间的块号相同时才会有序,其余时候还是疯狂地乱跳,那么每一次最坏就要跳 n n n次!对于每一个块,排序执行第二关键字: r r r。所以这里面的r是单调递增的,所以枚举完一个块, r r r 最多移动 n n n 次。总共有 n / s i z e n/size n/size 个块:复杂度为: O ( n ∗ n / s i z e ) O(n*n/size) O(n∗n/size)
总结: O ( n ∗ s i z e + n ∗ n / s i z e ) O(nsize+nn/size) O(n∗size+n∗n/size)(n,m 同级,所以统一使用n)
可惜都不太会
-
1
nzhtl1477 @ 2023-5-27 19:56:10
#include <iostream> #include <stdio.h> #include <vector> #define MAXN 1000010 using namespace std; int n , m; int a[ MAXN ] , pre[ MAXN ] , last[ MAXN ] , c[ MAXN ] , ans[ MAXN ]; vector < pair < int , int > > query[ MAXN ]; int find( int x ) { x++; int ans = 0; for( int i = x ; i > 0 ; i -= i & -i ) ans += c[i]; return ans; } void modify( int x ) { x++; for( int i = x ; i <= n ; i += i & -i ) c[i]++; } inline int read() { int x = 0 , ch = getchar(); while( !isdigit( ch ) ) ch = getchar(); while( isdigit( ch ) ) x = x * 10 + ch - '0' , ch = getchar(); return x; } int main() { scanf( "%d" , &n ); for( int i = 1 ; i <= n ; i++ ) scanf( "%d" , &a[i] ); for( int i = 1 ; i <= n ; i++ ) { pre[i] = last[ a[i] ]; last[ a[i] ] = i; } scanf( "%d" , &m ); for( int i = 1 ; i <= m ; i++ ) { int l , r; scanf( "%d%d" , &l , &r ); query[r].push_back( pair < int , int > ( l - 1 , i ) ); query[l - 1].push_back( pair < int , int > ( l - 1 , -i ) ); } for( int i = 1 ; i <= n ; i++ ) { modify( pre[i] ); for( int j = 0 ; j < query[i].size() ; j++ ) if( query[i][j].second > 0 ) ans[ query[i][j].second ] += find( query[i][j].first ); else ans[ -query[i][j].second ] -= find( query[i][j].first ); } for( int i = 1 ; i <= m ; i++ ) printf( "%d\n" , ans[i] ); return 0; }展开源码
-
1
#include<bits/stdc++.h> #define ll long long #define mod 100000000 using namespace std; const ll N=1000005; int n,m,k,s,t,b[N],pre[N],a[N],ans[N],l; struct node{ int id,x,y; bool operator<(const node &k)const{ return y<k.y; } }c[N]; void add(int k,int p){ while (k<=n){ b[k]+=p; k+=k&(-k); } } int query(int k){ int ans=0; while (k){ ans+=b[k]; k-=k&(-k); } return ans; } int main() { scanf("%d",&n); for (int i=1;i<=n;++i){ scanf("%d",&a[i]); pre[i]=b[a[i]];//求出每个位置的前置数字位置 b[a[i]]=i;//更新当前值为a[i]的最后一个位置 } cin>>m; for (int i=1;i<=m;++i){ scanf("%d%d",&c[i].x,&c[i].y); c[i].id=i; } sort(c+1,c+1+m);//离线,按照询问右端点排序 memset(b,0,sizeof(b)); l=1;//指针 for (int i=1;i<=m;++i){ while (l<=c[i].y){ if (pre[l]>0) add(pre[l],-1);//前置位置-1 add(l,1);//当前位置+1 ++l; } ans[c[i].id]=query(c[i].y)-query(c[i].x-1); } for (int i=1;i<=m;++i) cout<<ans[i]<<endl; } -
1
解题背景
最近在整理树状数组模板的时候偶然发现了一篇压箱底的ACcode,打开一看发现是这道HH的项链,早已经忘记了题面于是打开又看了一眼。一眼扫过去,~这不是个模拟吗~,然后看到数据范围:对于所有数据 :�,�≤1×106n,m≤1×106
……(妈耶那我凉了啊),怎么后面还有一句
本题可能需要较快的读入方式,最大数据点读入数据约20MB
噫。那行吧,想一想正解是什么东西。既然是从树状数组板子旁边揪出来的那就是树状数组咯,然而很闲的我又喵到了刚刚打完的线段树板子……线段树……?
翻了一下其他题解,这可能是唯一一篇同时讲解了线段树和树状数组两种常见做法的解题报告,所以就筹划着写下来了。至于其他julao们写的主席树、莫队、离散化、分块……本蒟蒻一个都不会,就不在此班门弄斧了。
核心思想
最大那个点*(#10)*数据有20��20MB,这已经不是普通的
scanf能承受的了。也许关了流同步的cin可以过,我没有试。所以上手先来一个快读,在此就略过。读一下题目,我们发现一句话,也就是他的问题:“某一段贝壳中,包含了多少种不同的贝壳?”。这句话里包含了两个意思:1. 询问的是一个区间,2. 对于同一种贝壳,如果在询问的区间中重复出现,那么就可以只关注它出现的某一个位置而忽略其他同类的贝壳。
事实上,这两点也就是这道题目的核心思想。那么接下来要考虑的就是,我们要关注在区间内哪一个位置的同类贝壳。因为在一个区间中除了端点以外,其它中间元素的位置和数目都是不确定的,所以一种思路显而易见:只关注在两端点处出现的同类贝壳。第一篇高赞题解说的也就是这个事情,他选择了右端点作为判断的标准,其实左端点当然也可以~~(只要反着建树就好了)~~。但是完全没必要把整个树状数组反过来,所以在此也仅讨论取最右边一个同类贝壳的情况。
既然只关注最右边的贝壳,那么就需要依次从左向右地处理和修改整个数组,这样才能保证我们对于前一个区间的修改不会影响到后面区间的询问。当然还有一点,在关注了最右边贝壳之后,要忽略区间内其他同类的贝壳。
还有一个问题,我们要对区间询问什么东西?这就涉及到前缀和的思想:对于每一个区间,询问在它右端点之前有多少不同类的贝壳。因为由于我们之前的修改操作,所有同类的贝壳已经被简化到只剩最靠右边那个,所以可以保证这种做法的正确性。
所以经过总结,我们可以得到这样的总思路:
- 我们需要一种支持单点修改、区间查询的数据结构
- 对给定的询问区间,按照区间右端点进行排序,按排序后的顺序记录答案,然后原序输出。
- 每个询问区间的答案就是区间右端点的前缀和−−(区间左端点−−1)的前缀和。
由此我们引出此解题报告的主角:树状数组和线段树。
树状数组解法
思路
单点修改、区间查询前缀和,树状数组真是一个再好不过的选择了。首先当然要开一个结构体存储询问的各个区间,方便排序和原序输出,再写一个
cmp:struct QUE{ int l; int r; int id; // 存放原序 }q[maxn]; inline bool cmp(const QUE &a,const QUE &b){ return a.r<b.r; }然后就是树状数组的几个板子,������lowbit,������modify以及�����query,在此也不多解释:
inline int lowbit(int x){ return x&(-x); } void modify(int p,int v){ for(;p<=n;p+=lowbit(p)) tree[p]+=v; } int query(int p){ int res=0; for(;p;p-=lowbit(p)) res+=tree[p]; return res; } // tree数组即为树状数组下面引入重要的一个数组
vis[]以及一个变量pow。vis[i]表示第i种贝壳在目前询问到的区间中最后出现的位置(也就是最右端)。变量pow指向的位置是尚未修改的区间的左端点,也就是已经修改区间右端点的后一个位置,方便定位未修改的区间。由于我们已经对询问的区间按右端点排好序,所以pow的值在不同时刻单调递增,直至末尾。有了以上的信息之后就我们可以对区间进行修改了,主要维护两个操作:
- 如果某元素
i在之前已经出现过,那么将其以前最右端位置的前缀和−−1,相当于忽略之前的位置。再在现在i的位置把前缀和+**+**1,并更新vis[i]到当前位置。 - 如果某元素
i在之前没有出现,那么直接修改当前位置前缀和即可,并更新vis[i]。
最后再算一下当前询问区间的答案即可,以上两个操作如下:
int pow=1; for(rint i=1;i<=m;++i){ for(rint j=pow;j<=q[i].r;++j){ if(vis[a[j]]) modify(vis[a[j]],-1); modify(j,1); vis[a[j]]=j; } pow=q[i].r+1; ans[q[i].id]=query(q[i].r)-query(q[i].l-1); }总代码
#include<iostream> #include<cstdio> #include<algorithm> #define rint register int #define maxn 1000010 using namespace std; int n,m; int a[maxn],ans[maxn]; int vis[maxn],tree[maxn]; struct QUE{ int l; int r; int id; }q[maxn]; inline void read(int &x){ char ch=getchar();int f=1;x=0; while(!isdigit(ch) && ch^'-') ch=getchar(); if(ch=='-') f=-1,ch=getchar(); while(isdigit(ch)) x=x*10+ch-'0',ch=getchar(); x*=f; } inline bool cmp(const QUE &a,const QUE &b){ return a.r<b.r; } inline int lowbit(int x){ return x&(-x); } void modify(int p,int v){ for(;p<=n;p+=lowbit(p)) tree[p]+=v; } int query(int p){ int res=0; for(;p;p-=lowbit(p)) res+=tree[p]; return res; } int main(){ read(n); for(rint i=1;i<=n;++i) read(a[i]); read(m); for(rint i=1;i<=m;++i){ read(q[i].l); read(q[i].r); q[i].id=i; } sort(q+1,q+m+1,cmp); int pow=1; for(rint i=1;i<=m;++i){ for(rint j=pow;j<=q[i].r;++j){ if(vis[a[j]]) modify(vis[a[j]],-1); modify(j,1); vis[a[j]]=j; } pow=q[i].r+1; ans[q[i].id]=query(q[i].r)-query(q[i].l-1); } for(rint i=1;i<=m;++i) printf("%d\n",ans[i]); return 0; } -
0
从9月二号起,在本平台本作者会进行暑假的救赎,兄弟们可以关注进度 本题解仅仅提供易错思路,不对整体思路进行讲解 同志们如果运行不过去了,可以来769147的题解观察。 易错点 pre[i] = 0 不可以为0 处理方法加入树状数组时所有数加一
#include <bits/stdc++.h> using namespace std; int a[1000005],pre[1000005],vis[1000005],c[1000005],n,m; struct Qui{ int l,r,ans,id; }; Qui q[1000005]; bool cmp1(Qui a,Qui b) { return a.r < b.r; } bool cmp2(Qui a,Qui b) { return a.id < b.id; } int lowbit(int x) { return x & (-x); } void add(int x,int k) { for(; x <= n ; x += lowbit(x)) { c[x] += k; } } int sum(int x) { int ans = 0; for(; x; x -= lowbit(x)) ans += c[x]; return ans; } int main() { ios::sync_with_stdio(false); cin.tie(0); cin >> n; for(int i=1; i <= n;i++) cin >> a[i]; for(int i=1; i <= n;i++) { if(vis[a[i]] > 0) pre[i] = vis[a[i]]; vis[a[i]] = i; } cin >> m; for(int i=1; i <= m ;i++) { cin >> q[i].l >> q[i].r; q[i].id = i; } sort(q+1,q+m+1,cmp1); int j = 1 , i = 1; while(i <= n && j <= m) { while(i <= q[j].r) { add(pre[i]+1,1); i++; } while(i > q[j].r && j <= m){ q[j].ans = sum(q[j].l) - q[j].l + 1; j++; } } sort(q+1,q+m+1,cmp2); for(int i=1; i <= m ;i++) { cout << q[i].ans << endl; } }
- 1